Expressing numbers of how long something took to produce without expressing how big that product is, nor that product’s capacity to perform, makes it hard for anyone else to grasp and compare against their own conceptions of products and implementations. Sure, in four years 2 major versions of a “warehouse operating system” were produced and used in four different customer implementations – but how big and complex was the codebase and how involved were the customer implementations?
There are all sorts of ways to measure the magnitude of a software system, but none of them are reliably great ways to measure the complexity nor the “value-producing” carrying capacity of the system. As in all engineering, there are usually trade-offs for different outputs and inputs and constraints that a single measure cannot rationalize in clean linear throughput.
We can measure the point-in-time lines-of-code and number-of-files (and the ratios between them grouped at varying functional scopes if necessary). But the number of lines – even if limited to “essential” executable lines – does not really tell how many lines are useful, nor valuable, nor code quality, nor anything like that.
Measuring code check-in flows versus ultimate size of code units may tell us code flux (over time), and possibly how well the code is assumed to fit the function by any developer or design team or tester at any point in time, or even how buggy it may have been perceived at any point in time.
WOS Code Cardinalities
Measure something like lines of code within a relatively homogenized codebase is not without merit, if we assume the same designer/coder using a consistent implementation pattern; a rough rationalization is probably justifiable under these conditions. The design and implementation of the WOS kernel’s codebase rests largely on myself, so I believe I can justify some inferences, and can provide enough narrative insight to make sense of the magnitudes of the remaining code – for those functional areas in which I was not the primary or sole developer.
WMS/WES Intralogisitcs Kernel
First up, the intralogistics kernel, these are the modules/packages in which my hand did most of the heavy lifting.
The base kernel is derived from some of my past experiences with web-like service-based architecture (with relatively modern object-oriented programming paradigms such as ERM, DI and a host of other pattern-tagging initialisms too dense to deal with here and now), and ways to optimize and secure them. Long term supportability by an organization was also a key ingredient, and due to the async problem-solving nature of intralogistics (fix it after we discover it went wrong on-site), our need to reliably track and trace operations, containers and interactions with the system was a heavy consideration that needed its own sub-system of information processing and process-oriented tracking.
Upwards towards the intralogistics functions of the kernel, I was able to include refinements and realizations of various intralogistic concepts that had been loosely modeled in legacy code from the company’s history; that is, I could “mine” legacy code for abstractions via data schemas, stored-procedures and various application code artefacts.
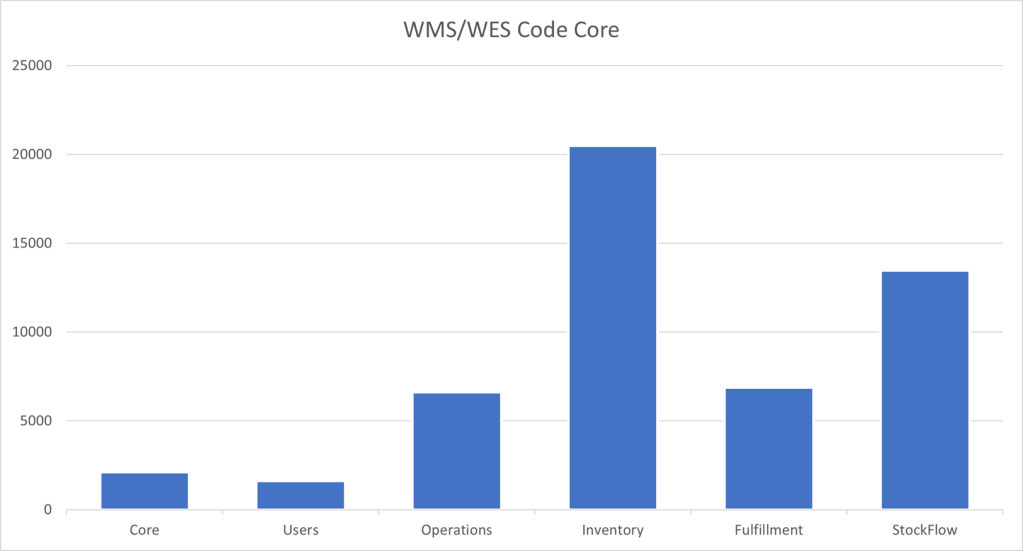
| Package | Files | Lines of Code |
|---|---|---|
| Core | 67 | 2120 |
| Users | 47 | 1616 |
| Operations | 140 | 6631 |
| Inventory | 328 | 20503 |
| Fulfillment | 159 | 6887 |
| Stockflow | 202 | 13477 |
Core
The core is relatively small, with a large percentage of the files/code occupying the refreshable singleton dependency lookup management framework. In addition, the shared database connection, transactional commit processing and system startup bootstrapping code are all found in here, so despite the small size, everything significant that happens goes through code in here in some way.
The core is analogous to the ball-bearings and grease of the system. The system runs smoothly and better than it might otherwise because of what’s in the core. Core is small but mighty necessary.
Users
The users package is even smaller than core. Users come into play in the user interface part of the system, and for audit tracking when appropriate. A simple user to group, and group to permission data-model provide access visibility and API call security when necessary (for user-bound web-calls).
Basically: User <–> Group <–> Permission.
In addition, salted/hashed password credential support is included here for systems that do not provide external authentication. In a pure automation system with no user interface, this package may never be involved, or only on the periphery for monitoring and exception and utility inventory processing.
Operations
The operations package is larger than the first two combined. Unlike the users, there are multiple data schemas and functionalities that need to be handled to ensure traceability for audit and problem solving.
Operations are logical functional units of processing in the warehouse operating system. Every significant change within the inventory system must take place in the context of an operation. An operation can span multiple interactions (which are also defined in the operations assembly), which occur within a session from an access device.

The reason for this level of “complexity” is to ensure automation equipment and user devices can be tracked and logged in the activity tracking system, and that operations are performable from appropriate devices.
The operations package defines and implements the data-bound logging system for the operations per se (not shown in the following diagram…), inventory events, fulfillment events, automation/sort events, and stockflow/allocation events.

In addition, the recurring job agent and broker code are implemented in the operations package. Recurring operations perform activity on schedules and cycles within the context of agent sessions using agent access devices. An extensible “old-data” cleanup recurring job framework is defined here as well, with default implementations for the event logs.
Inventory
The inventory package is the largest component of the intralogistics kernel. Functionally it covers containers & contents, item definitions, locations, zones (of locations) and zone groups (of zones and other zone-groups). Given its functional coverage as the WMS package (or at the very least the IMS…inventory management system), its relative size is warranted.
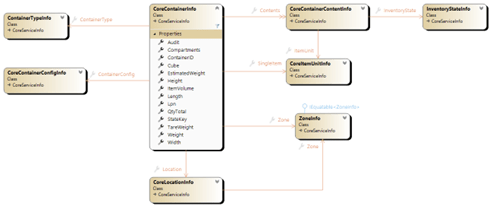
All logical data management services for tracking and rule validation involving inventory occur here, including: moving containers; moving pieces into, out of, and between containers; creating and destroying containers; and handling inventory state transitions (for process flow control and tracking). Likewise, system for processing rules based on location accessibility and validity are also defined and enforced within this package.
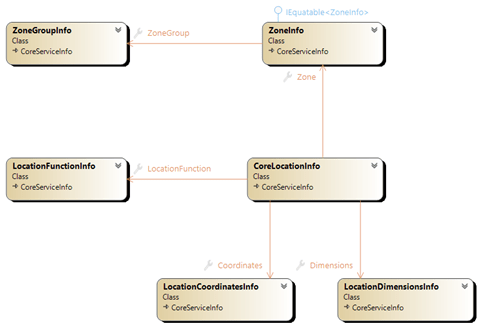
Warehouse topology is stitched together via zone groups, zones and locations and made searchable via a service interface; providing local decision-making context for workstations and allocation processors.
Fulfillment
The fulfillment package has a robust capacity to model a variety of order types, requirement types, address usages, package types, and intermediate processing entities for order fulfillment workflows. The services allow for creating, modifying, deleting and processing order requirements and order requirement demands (sub-steps in an order requirement), planning packages, and packing requirements into packages.
Statuses of orders, requirements, and packages are expected to be calculated by evaluator class implementations defined in customization code and called from base code as needed during processing.
The footprint is relatively small based upon the relative regularity of order management within the WOS. The WOS is not intended to be a system or record for orders, but has a flexible enough abstract model to allow for mapping orders from host systems so they can be fulfilled and traced properly.
Or to put it more simply: the data-model is fairly “straightforward”, expecting “type-information” and evaluative state tracking to be configured during implementation design, and broad management of orders to be handled by host system messaging. The fulfillment system support fulfillment processing as a meticulous book-keeper to assist in evaluating order completion, most of its model is to support the customization while having consist process tracking.
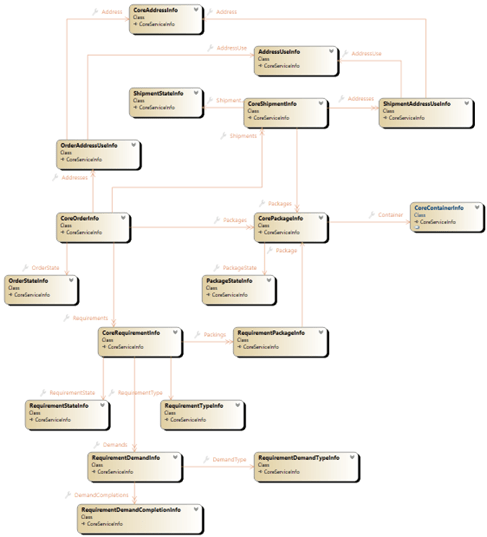
Over time, fulfillment order “styles” are expected to migrate into the fulfillment core of the system from abstracted customer patterns noticed by implementation and product teams. In that way “Types” and “States” (with their transitional flow graphs) would become more standardized.
StockFlow
The stockflow package relies heavily on the inventory system. It is relatively large in terms of code lines and files, as it covers the logical model and pragmatic processing services and engines for the abstract WES functionality of the WOS.
- stock provisioning: storing inventory capable of being reserved and provisioned for allocated demand elsewhere in the warehouse; reservation processing itself; and default provisioning implementations capable of being extended for specific customer strategies
- stock consumption: maintaining demand-based quantitative plans to use inventory, specific sets and containers of inventory earmarked to fulfill (partially or completely) the demand, and what generated the specific line-items of quantity.
- strategies: defining potential connections of inventory use between providers (provisioning) and consumers (consumption) by strategy type, allows often to scale up by adding consumers or producers that can process the same strategy, even if in different physical modes of allocated delivery.
- container delivery and unit-pooling: strategy types that specifically do not involve deterministic use (i.e., pooling is non-deterministic in allocated use) and for moving containers that do not need special consumption demand tracking – such as inventory control processing strategies (COUNT, PURGE, INSPECT) that just need containers delivered for special processing.
- default implementations: allocators to match plan demand, deallocators to decrease if plan demand decreases, provisioners for detail plan and replenishment strategies, stock tracking recurring agent pollers to ensure inventory reservable levels are accurate, and work-in-progress governors to ensure singles processing stations (that use unit pools) are properly fed and do not overwhelm a shared delivery system.
Stopping Point
I wanted to cover more, but feeling that I’ve hit enough for now. This post covers the WMS/WES side of the intralogistics kernel codebase. Hopefully later, I’ll cover the WCS/WES aspects, probably in less detail.
