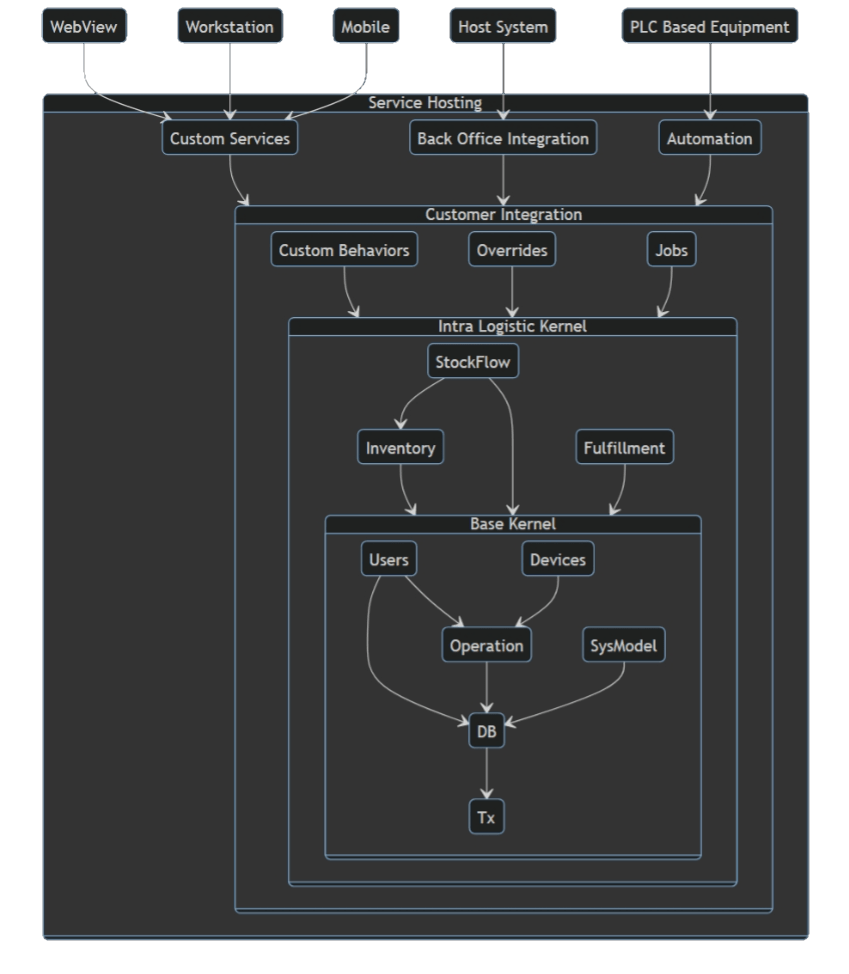
The layered design of HyperCore is explored by introducing the concepts of kernels.
Kernel
A kernel is shared software providing immutable or abstract services to system integration code and customer application code. Just about every word in that sentence can be further unpacked, but as a “kernel-level” topological model for context in understanding HyperCore, it’s a suitable anchor point.
The HyperCore kernel has several service categories:
- base-kernel system management functions operating relatively close to the base .NET platform
- intralogistical-kernel functions providing warehouse operational behaviors and services
The ancestral code-base preceding HyperCore included both common libraries and “semi-morphic” code-reuse (that is, by copy/mutate). Common libraries provided system integration support, and copied and altered “reused” code provided the intralogistical logical structure of the new application code.
Base-Kernel Services
Common components of HyperCore providing functions that are not specific to intralogistical operations.
These functions include:
- database support such as transaction control, SQL schema redirection and shared connection management.
- read-access and write-refresh for slowly changing lookup values avoiding chronic database reads
- system model, setting management and boot-loading to support runtime service hosting
- access devices and users
- logical transient and durable operations
- schedulable recurring operations
- logging
Intralogistic-Kernel
The intralogistic-kernel is centered around three major warehouse concerns: basic inventory management, fulfillment modeling and flow control.
The basic inventory management models and services encompass material and locations and cover the following:
- inventory item templates – properties and part relationships
- container model – LPN, configuration, type
- locations – functional use
- location topologies – zones and zone groups within purposeful functional units
- inventory quantities with stateful process tracking and constraints
The fulfillment tracking model handles orders in a general sense, and has been adapted to in-store fulfillment and redistribution models:
- orders
- requirements needed to complete the orders
- intermediate demand modeling to complete requirements
- progress tracking against demands and requirement feeding custom tailored status state identifiers
- packages
- shipments
Dependency on the inventory system is not-mandatory, but several of the modeled fulfillment concepts are designed to support inventory and container integration.
The third leg of the intralogistical kernel is StockFlow:
- inventory stock-levels – in aggregate and by provisioning zone
- reservation management – allocations against the inventory in general
- provisioning – finding matches of inventory for reservation demands
- allocation system – providing an inventory consumption-use based model to track and balance flow
The expected integration with the inventory system is higher than with the fulfillment system, and it provides certain hooks that make integrating with the fulfillment system simpler for specific scenarios; however, it does not provide allocations just for fulfillment, and can “direct” container moves for stateful processing or relocation.
